Na lição 2 analisámos as cartas de controlo Xbar e Range. Na lição 4, foi introduzido o gráfico X (valor individual). Em ambos os casos, utilizámos dados variáveis ou de medição. Estes são dados que provêm de uma escala contínua.
Há um tipo diferente de dados chamado dados de “Atributo“. Os dados de atributo provêm de contagens discretas. Por exemplo:
– o número de manchas numa superfície,
– o número de produtos defeituosos,
– o número de facturas por pagar.
Com dados do tipo de atributo, a fim de escolher o tipo correcto de carta de controlo, temos de olhar para a forma como os dados foram gerados. Se soubermos antecipadamente que o conjunto de dados exibirá as características dos Dados Binomiais ou Dados Poisson, então estes tipos de gráficos devem ser utilizados.
Dados Binomiais:
Os dados binomiais são onde os itens individuais são inspecionados e cada item ou possui o atributo em questão ou não possui. Binomial significa “dois nomes”, por isso, se cada item puder ser registado como um passe ou um erro, então podemos considerar os dados recolhidos como dados binomiais.
Por exemplo, considerar o atributo “azul” em amostras de esferas recolhidas de uma caixa que contém esferas de muitas cores. Cada esfera recolhida ou é azul ou não é azul – portanto, se criarmos um fluxo de amostras retiradas da caixa e contarmos o número de esferas azuis nas amostras, então podemos assumir que os dados resultantes serão dados do tipo Binomial.
Outros exemplos de contagens que gerariam dados binomiais são:
– Entregas tardias,
– Bens não conformes,
– Componentes fora das especificações.
A variação aleatória dos dados binomiais acua de uma forma particular, por isso podemos calcular onde colocar os limites de controlo. Tudo o que precisamos de saber é a média do conjunto de dados e o tamanho da amostra.
Podemos gerar dados Binomiais utilizando a simulação de esferas de amostragem a partir da caixa – por isso vamos fazer isto agora. A caixa de esferas tem 20% de produtos vermelhos (maus) e 80% de produtos brancos (bons):
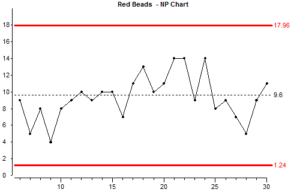
Este tipo de gráfico é chamado de gráfico “np”. É utilizado quando sabemos que temos dados binomiais e o tamanho da amostra não se altera. Os pontos no gráfico np são simplesmente o número de itens da amostra que têm o atributo a ser contado (neste caso estamos a contar contas com o atributo “vermelho”)
Vejamos brevemente como foram calculados os limites de controlo:

Nestas fórmulas “n” é o tamanho da amostra (neste caso 50, o tamanho da pá), e “p bar” é a proporção média das amostras que têm o atributo a ser contado.
Dados Binomiais com diferentes tamanhos de amostras:
Se tivermos dados binomiais mas o tamanho da amostra não for constante, então não podemos utilizar um gráfico np. Vamos agora utilizar a simulação para adicionar novas amostras aos dados que já começámos, mas vamos alterar o tamanho da amostra:
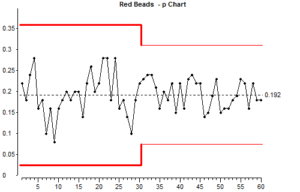
Quando o tamanho da amostra não é constante para cada colher, temos de converter as contagens para uma taxa ou proporção. O gráfico resultante é chamado de Gráfico “p”. Convertemos para uma taxa, dividindo a contagem de atributos pelo tamanho da amostra.
Notará que existe uma etapa nas linhas limite de controlo, no ponto em que o tamanho da amostra mudou. Antes de olharmos para a matemática dos limites de controlo, vamos tentar compreender porque existe uma etapa.
O objetivo dos limites de controlo é mostrar os valores máximos e mínimos que podemos reduzir à variação aleatória da causa comum. Quaisquer pontos fora dos limites indicam que provavelmente ocorreu algo mais para fazer com que o resultado esteja mais longe da média.
Como já dissemos anteriormente, a variação aleatória da causa comum dos dados Binomiais atua de uma forma particular. A variação com tamanhos de amostras grandes é menor do que a variação com tamanhos de amostras pequenas. Podemos utilizar a simulação para demonstrar isto.
Vamos alterar o tamanho dos subgrupos para 5 e tirar mais 30 subgrupos:
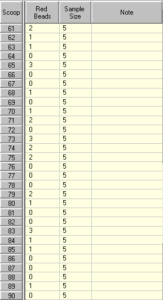
Veja os resultados na Tabela de Dados e tenha em mente que a proporção de esferas vermelhas na caixa não se alterou. Neste exercício, há sempre 20% de esferas vermelhas numa caixa.
Quando o tamanho da amostra é 5, muitas vezes o número de esferas vermelhas recolhidas é 1 (20% do tamanho da amostra), mas não é invulgar obter 0 ou ocasionalmente 3 (60% do tamanho da amostra). Em casos raros, como nesta simulação, podemos até ter 4 e temos um falso alarme.
Agora vamos usar um tamanho de amostra muito grande:
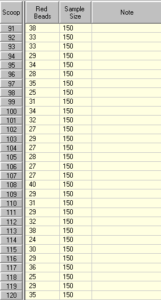
Veja novamente os resultados na Tabela de Dados. Lembre-se que 20% das esferas na caixa são vermelhas e 20% da média do tamanho da amostra é agora de 30.
Como seria de esperar, a maioria dos resultados estão perto dos 30, mas mesmo os resultados mais extremos não estão nem perto de 0% ou 60% do tamanho da amostra (60% do tamanho da amostra seria 90). Vejamos agora como a carta de controlo lida com estes tamanhos extremos de amostra.
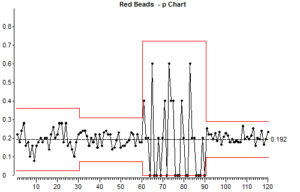
Observar a forma como os pontos que correspondem ao tamanho da amostra pequena (amostras 60 – 90) variam para cima e para baixo, depois comparar isto com a variação com o tamanho da amostra grande (depois de 90). Tenha em mente que não estamos a olhar para números absolutos aqui, estamos a olhar para a proporção da amostra que é vermelha.
Olhe para a posição dos limites de controlo para o tamanho dos subgrupos pequenos e para o tamanho dos subgrupos grandes.
Isto ilustra um dos pontos básicos sobre a utilização de cartas de controlo para os atributos. Os subgrupos pequenos produzem gráficos de controlo que não são sensíveis porque há tanta variação aleatória das causas comuns em amostras de tamanho pequeno. Os tamanhos de amostras grandes produzem gráficos de controlo mais sensíveis.
O que isto significa é que se um processo tiver uma causa especial de variação agindo sobre ele de tempos a tempos, pode não produzir quaisquer pontos fora dos limites de controlo se o tamanho da amostra for pequeno. A mesma causa especial de variação é mais susceptível de produzir pontos fora dos limites de controlo se utilizarmos um tamanho de amostra grande.
Vejamos rapidamente a matemática para os limites de controlo:

Note-se que os limites têm de ser calculados separadamente para cada tamanho de subgrupo. O exemplo dado é para a amostra número 1 (subgrupos de 1 a 30).
Critérios para os Dados Binomiais:
Só podemos utilizar um gráfico np ou um gráfico p se soubermos antecipadamente que os dados produzidos serão dados binomiais. As condições completas que têm de ser satisfeitas antes de podermos considerar um conjunto de dados como Binomial são:
- A contagem deve resultar de um número conhecido de produtos discretos (bens ou serviços).
- Cada produto inspeccionado deve ter, ou não ter, o atributo que estamos a contar.
- Os produtos inspecionados não devem influenciar os outros. Se um item tem o atributo, este facto não deve alterar a probabilidade dos seus vizinhos terem o atributo.
Sumário Lição 5:
- Os dados do processo podem ser divididos em duas grandes categorias, variáveis e atributos.
- Os dados binomiais são dados de atributos em que os itens individuais são inspeccionados e cada item ou possui o atributo em questão ou não.
- Um Gráfico “np” é utilizado para dados binomiais se o tamanho da amostra for constante.
- Um Gráfico “p” é utilizado para dados binomiais se o tamanho da amostra não for constante.
- Antes de utilizar um gráfico “np” ou um gráfico “p” temos de nos certificar de que todas as condições para os dados binomiais são cumpridas.
- Com a aplicação do SPC à contagem de atributos, as amostras de pequenas dimensões tornam difícil distinguir entre variação de causa comum e variação de causa especial.