One of the most important names in the history of statistical process control is Deming as explained in the prior lesson. Deming used a famous simulation to explain the principles of variation called: The Red Bead Experiment. While explaining the principles of variation we like to honor Deming by using his red bead box. In this lesson we are going to explain the principles of variation and how we will analyze variation using control charts.
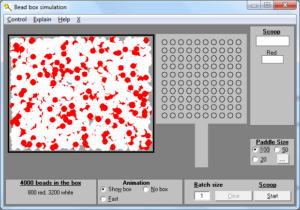
Imagine that you are interested in a process and you want to get better results from that process. It may be a manufacturing process or a service process, it may be in the public sector or you may work for a private company. We are going to count a particular type of thing which you would prefer did not happen. We will scoop beads from a box to simulate the process and any red beads scooped are going to represent the thing you would prefer to avoid
We can take a number of scoops from the box and we can count the number of red beads drawn with every scoop.
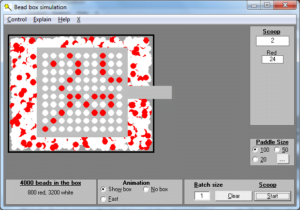
The point to understand here is that it is random variation which is producing the different number of red beads in each scoop. Every process contains some random variation and the people who operate the process have no control over it.
Let’s now look at a table of the results:
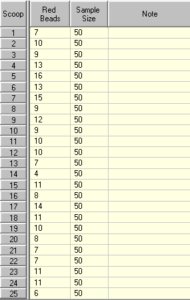
Now, suppose that we did not know that these results were due to random variation. Say, for example, that the figures come from a school and represent the number of pupils expelled for bad behavior each year.
Translate the numbers you find into headlines in your local newspaper:
“Big jump in expellings from school – officials want to know why”
“The number of expelled pupils has fallen since the new headmaster took over.”
“Number of expelled pupils has increased for 3 years in a row. Experts blame video games.”
It is very easy to fall into the trap of assuming that there is always a reason for figures going up or down. There is no reason – other than random variation – to explain why the number of red beads drawn by the paddle changes with every scoop. Every year, random variation alone will cause a different number of pupils to enter the school system with behavior problems.
Let’s look how this information would look in a chart:
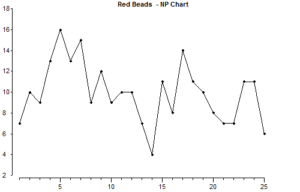
This is what random variation looks like. Putting past results in time sequence on a chart like this should make us less likely to jump to conclusions about an individual result. We might be less likely to assume that an upward or downward trend of just 3 or 4 results means that a long-term change is taking place.
However, we do need to know if a new policy, or a change in procedures, or a change to a process really affects the results. So we need something which points out the significant changes and encourages us to ignore the random variation. This is where control limits come in.
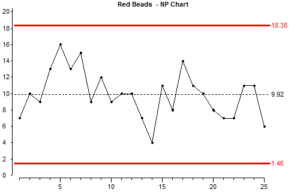
If we use the simulation to add new points on the chart all points should be between the control limit lines (although you might be unlucky and get a false signal).
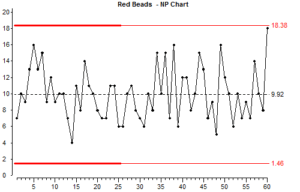
Although there are lots of ups and downs on the chart, you should be able to get an overall impression that this process is stable. There is no obvious change over the long term.
In this process, whatever causes the low counts also causes the high counts. The things which cause the variation are common to all the results. That is why this type of variation is called common cause variation.
We also say that the results are “in statistical control”. We say this because as long as nothing changes, we can predict that this process will continue with approximately the same average, and the control limits will continue to show the maximum and minimum results that we can expect.
Now we will look at a set of results from a very different type of process
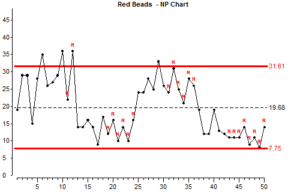
You will notice that this process has about the same average number of defects as the previous chart but the chart looks very different.
This chart is showing that the process is unstable. There are two things on the chart which indicate instability:
- some points are outside the control limit lines
- some points have an “R” above them which indicates a “run”. The previous 6 points are on the same side of the average – it is unusual for random variation to produce 7 consecutive points above average or 7 consecutive points below average.
With this process, there is something else affecting it alongside the common causes of variation. Look at the results between 25 and 37 on the horizontal scale and compare them with the results between 37 and 50. Something must be causing them to be different. We call this a “special” cause of variation.
When special causes of variation are present in a process we say that the process is “unstable”. With an unstable process you cannot predict future results because we do not know when the special causes of variation will occur. If we have an unstable process, we should, whenever possible:
- investigate what is causing the special variation,
- learn whatever we can from the investigation
- improve the process by making the best conditions permanent
- put controls in place to prevent the special variation from returning
In the simulation we have arranged that no more special variation will occur, so we can scoop more beads. But first we will write a note on the control chart:
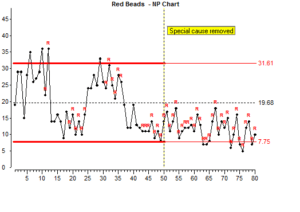
We scoop 30 more subgroups and there seems to be consistently fewer red beads now and the red beads represent something that we do not want. So there is reason to believe that we have improved this process.
We should now recalculate the control limits using results which come after the improvement.
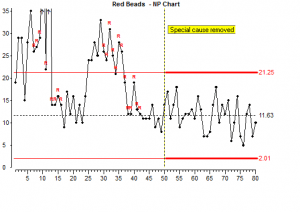
We now have new control limits which indicate the limits of common cause variation for the new improved process.
These new limits will show if any new special causes of variation appear. If one does appear, we should investigate it and remove it.
If we want to improve a process which contains only common cause variation, we will need to investigate the factors which are constantly affecting the process and influence every result
Summary Lesson 1:
- All processes contain variation.
- We must distinguish between special cause variation and common cause variation. We need to know this difference because the things we will have to do to remove or reduce the two types of variation are very different. We need to reduce variation to improve processes.
- The way to distinguish between common cause variation and special cause variation is to use a control chart.
- Before we can consider a process to be “under control”, efforts must be made to remove special causes of variation. We must also learn from each incident of special variation and take action to make sure that these types of changes do not happen again.
- If we want to improve a process which contains only common cause variation, we need to investigate the factors which affect every result.