En la lección 2 vimos los gráficos de control Xbar y Range. En la lección 4 se introdujo el gráfico X (valor individual). En ambos casos, utilizamos datos variables o de medición. Se trata de datos que provienen de una escala continua.
Hay un tipo diferente de datos llamados datos de “atributos”. Los datos de atributos provienen de recuentos discretos. Por ejemplo
– el número de manchas en una superficie,
– el número de productos defectuosos,
– el número de facturas impagadas.
Con los datos de tipo atributo, para elegir el tipo correcto de gráfico de control, tenemos que fijarnos en la forma en que se generaron los datos. Si sabemos de antemano que el conjunto de datos va a presentar las características de los datos binomiales o de los datos de Poisson, entonces deben utilizarse estos tipos de gráficos.
Datos binomiales:
Los datos binomiales son aquellos en los que se inspeccionan los elementos individuales y cada elemento posee el atributo en cuestión o no lo posee. Binomio significa “dos nombres”, por lo que si cada elemento se puede clasificar como un aprobado o un suspenso, podemos considerar que los datos recogidos son datos binomiales.
Por ejemplo, consideremos el atributo “azul” en las muestras de cuentas extraídas de una caja que contiene cuentas de muchos colores. Si creamos un flujo de muestras tomadas de la caja y contamos el número de cuentas azules en las muestras, podemos asumir que los datos resultantes serán datos de tipo binomial.
Otros ejemplos de recuentos que generarían datos binomiales son:
– Entregas tardías,
– Productos no conformes,
– Componentes fuera de especificación.
La variación aleatoria de los datos binomiales actúa de una manera particular, debido a esto podemos calcular dónde poner los límites de control. Todo lo que necesitamos saber es la media del conjunto de datos y el tamaño de la muestra.
Podemos generar datos Binomiales utilizando la simulación de sacar cuentas de la caja, así que vamos a hacerlo ahora. La caja de cuentas tiene un 20% de productos rojos (malos) y un 80% de productos blancos (buenos):
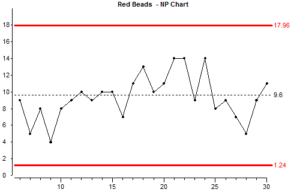
Este tipo de gráfico se llama gráfico “np”. Se utiliza cuando sabemos que tenemos datos binomiales y el tamaño de la muestra no cambia. Los puntos del gráfico np son simplemente el número de elementos de la muestra que tienen el atributo que se está contando (en este caso estamos contando cuentas con el atributo “rojo”)
Veamos brevemente cómo se han calculado los límites de control:

En estas fórmulas “n” es el tamaño de la muestra (en este caso 50, el tamaño de la paleta), y “p barra” es la proporción media de las muestras que tienen el atributo que se cuenta.
Datos binomiales con diferentes tamaños de muestra
Si tenemos datos binomiales pero el tamaño de la muestra no es constante, entonces no podemos utilizar un gráfico np. Ahora utilizaremos la simulación para añadir nuevas muestras a los datos que ya hemos iniciado, pero cambiaremos el tamaño de la muestra:
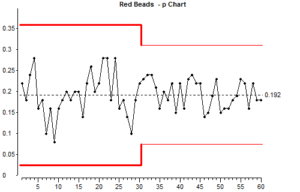
Cuando el tamaño de la muestra no es constante para cada cucharada, tenemos que convertir los recuentos en una tasa o proporción. El gráfico resultante se denomina gráfico “p”. La conversión a tasa se realiza dividiendo el recuento de atributos por el tamaño de la muestra.
Observará que hay un paso en las líneas de límite de control en el punto en el que cambió el tamaño de la muestra. Antes de ver las matemáticas de los límites de control, tratemos de entender por qué hay un escalón.
El propósito de los límites de control es mostrar los valores máximos y mínimos que podemos atribuir a la variación aleatoria de causa común. Cualquier punto fuera de los límites indica que probablemente ha ocurrido algo más para que el resultado se aleje de la media.
Como hemos dicho antes, la variación aleatoria de causa común de los datos binomiales actúa de una manera particular. La variación con tamaños de muestra grandes es menor que la variación con tamaños de muestra pequeños. Podemos utilizar la simulación para demostrarlo.
Cambiaremos el tamaño de los subgrupos a 5 y tomaremos 30 subgrupos más:
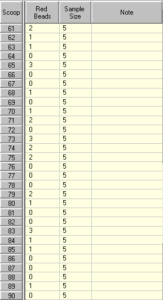
Observa los resultados en la tabla de datos y ten en cuenta que la proporción de cuentas rojas en la caja no ha cambiado. En este ejercicio siempre hay un 20% de cuentas rojas en la caja.
Cuando el tamaño de la muestra es 5, muchas veces el número de cuentas rojas recogidas es 1 (20% del tamaño de la muestra), pero no es raro obtener 0 u ocasionalmente 3 (60% del tamaño de la muestra). En casos raros como en esta simulación podemos tener incluso 4 y tenemos una falsa alarma.
Ahora usemos un tamaño de muestra muy grande:
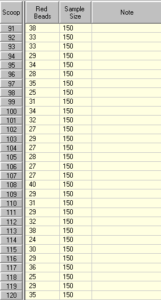
Observa de nuevo los resultados en la tabla de datos. Recuerde que el 20% de las cuentas de la caja son rojas y que el 20% de la media del tamaño de la muestra es ahora 30.
Como es de esperar, la mayoría de los resultados se acercan a 30, pero incluso los resultados más extremos no se acercan al 0% o al 60% del tamaño de la muestra (el 60% del tamaño de la muestra sería 90).
Ahora veamos cómo el gráfico de control maneja estos tamaños de muestra extremos.
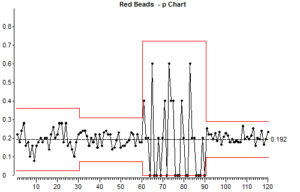
Fíjese en la forma en que los puntos que corresponden al tamaño pequeño de la muestra (muestras 60 – 90) varían hacia arriba y hacia abajo, y compárelo con la variación con el tamaño grande de la muestra (después de 90). Tenga en cuenta que no estamos mirando los números absolutos aquí, estamos mirando la proporción de la muestra que es roja.
Observe la posición de los límites de control para el tamaño de subgrupo pequeño y el tamaño de subgrupo grande.
Esto ilustra uno de los puntos básicos sobre el uso de gráficos de control para los atributos. Los subgrupos pequeños producen gráficos de control que no son sensibles porque hay mucha variación aleatoria de causa común en los tamaños de muestra pequeños. Las muestras de gran tamaño producen gráficos de control más sensibles.
Lo que esto significa es que si un proceso tiene una causa especial de variación actuando en él de vez en cuando, puede no producir ningún punto fuera de los límites de control si el tamaño de la muestra es pequeño. La misma causa especial de variación es más probable que produzca puntos fuera de los límites de control si utilizamos un tamaño de muestra grande.
Echemos un vistazo a las matemáticas de los límites de control:

Tenga en cuenta que los límites deben calcularse por separado para cada tamaño de subgrupo. El ejemplo dado es para la muestra número 1 (subgrupos 1 a 30).
Criterios para datos binomiales:
Sólo podemos utilizar un gráfico np o un gráfico p si sabemos de antemano que los datos producidos serán datos binomiales. Las condiciones completas que deben cumplirse para que podamos considerar que un conjunto de datos es binomial son
El recuento debe proceder de un número conocido de productos discretos (bienes o servicios).
Cada producto inspeccionado debe tener o no tener el atributo que estamos contando.
Los productos inspeccionados no deben influirse mutuamente. Si un producto tiene el atributo, este hecho no debe cambiar la probabilidad de que sus vecinos tengan el atributo.
Resumen de la lección 5:
1. Los datos del proceso pueden dividirse en dos grandes categorías, variables y atributos.
2. Los datos binomiales son datos de atributos en los que se inspeccionan los elementos individuales y cada elemento posee el atributo en cuestión o no lo posee.
3. Se utiliza un gráfico “np” para los datos binomiales si el tamaño de la muestra es constante.
4. Un gráfico “p” se utiliza para datos binomiales si el tamaño de la muestra no es constante.
5. Antes de utilizar un gráfico “np” o un gráfico “p” tenemos que asegurarnos de que se cumplen todas las condiciones para los datos binomiales.
6. Al aplicar el CEP a los recuentos de atributos, los tamaños de muestra pequeños dificultan la distinción entre la variación por causa común y la variación por causa especial.